Marc, tu as raison dans mon exemple c'est la lettre D qui est attendu et non le A comme je l'avais écrit.
Concernant la notation "Big O", ce n'est pas très compliqué mais fondamentale pour l'analyse de la vitesse des algorithmes indépendamment de l'implémentation.
http://bigocheatsheet.com/
Par exemple si tu dois examiner chaque élément d'une liste pour trouver la réponse à un problème, ton algo est de type O(n) cad que plus il y a d'éléments dans la liste (n éléments) plus ça sera proportionnellement long. C'est une droite.
Si pour chaque élément de la liste tu dois le comparer à chacun des autres éléments de cette même liste, tu fera n² itérations (soit une double boucle imbriquée). Dans ce cas, la courbe est quadratique au nombre d’éléments de la liste O(n²).
Cherche un élément en mémoire prend en moyenne un temps constant donc O(1)
Etc...
Selon le type d’algorithme et selon le nombre d’éléments traités, le but est de trouver un algo qui est calculable en un temps raisonnable.
Quelques exemples, en abscisse le nombre d'éléments, en ordonnée, le temps de traitement.
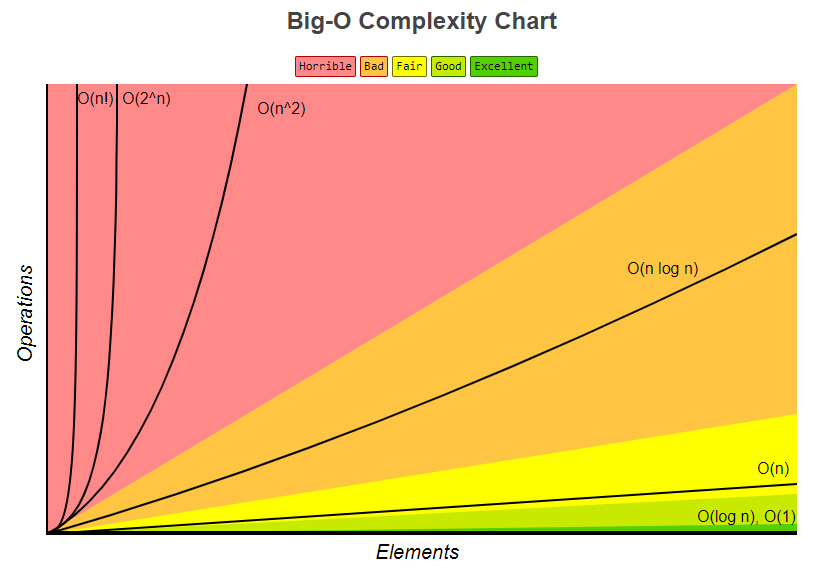
La réponse de GallyHC est O(n²) car chaque élément est comparé à tous les autres (la fonction findstring est une boucle en fait), la tienne O(n).
Celle de Ars qui utilise le tri des listes est O(n log n) -pour simplifier, mais en fait pire à cause des deux autres boucles-, en effet, le tri des listes chainées en Pb est un tri par fusion (il me semble).
Si il y a une complexité forte, ça reste acceptable dans la mesure où on traite peu d'éléments.
Il y a deux méthodes pour écrire des programmes sans erreurs. Mais il n’y a que la troisième qui marche.
Version de PB : 6.00LTS - 64 bits




