chr() and unicode

Hi Paul, I think the code page issue is a non-issue.. try saving a PB file as UTF-8 and then view the pb file in any UTF-8 compatible editor (ideally one that reports the encoding in the status area etc), and note what encoding it thinks the file is in.. It should report UTF-8. I've tried editplus & sakura editor, and they both report UTF-8. As for my setup, it's just my regular English OS setup for Japanese regional options (defaults for code page) and non-unicode program to display as Japanese (just for the odd non-unicode Japanese app). BTW the code pages includes UTF-8 ticked by default (but it's greyed out, and I think it's not really significant anyway - 932 is ticked however). I've never twiddled with these - never had to, and never had any issues.

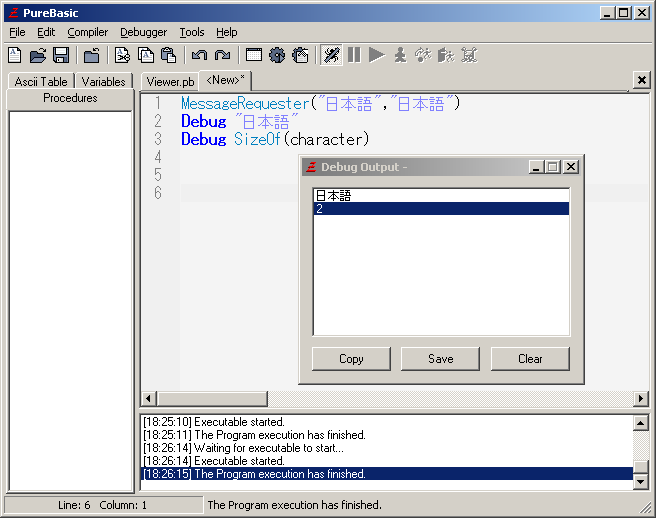
pdwyer, I'm curious. Are you using the internal debugger to output Japanese? I can't tell by your screenshot.
Freak says that it's only possible with the standalone debugger.
Freak says that it's only possible with the standalone debugger.

@Mistrel, I saw freaks comments, I think he means that the internal debugger doesn't support unicode (I didn't manage to get it to support unicode either). The screenshot is the internal debugger though and that's not a unicode app. In regional settings my PC will treat non unicode as codepage 932 (shift jis)
@mskuma, Seems we both have the same goal but we've picked up a different habbit of how to get there as our preference I was a big unicode fan when I used VB about 7-8 years ago then when I used powerbasic it had no support so I'd just handle the API as needed (netuseradd() etc ) then did all the rest in local code page. win2k's codepage 932 support was not too good though compared to XP. I'll have a play with the editor to see how it goes with utf8. Generally I find it easier not to bother with unicode unless I need to support more than one language on top of an alphabet based one... not very often thankfully.
I was a big unicode fan when I used VB about 7-8 years ago then when I used powerbasic it had no support so I'd just handle the API as needed (netuseradd() etc ) then did all the rest in local code page. win2k's codepage 932 support was not too good though compared to XP. I'll have a play with the editor to see how it goes with utf8. Generally I find it easier not to bother with unicode unless I need to support more than one language on top of an alphabet based one... not very often thankfully.
Personally, it seems that if utf8 was never invented, the world might have been a bit closer to getting to a clean utf16 standard that would get rid of all the code pages.
@mskuma, Seems we both have the same goal but we've picked up a different habbit of how to get there as our preference
Personally, it seems that if utf8 was never invented, the world might have been a bit closer to getting to a clean utf16 standard that would get rid of all the code pages.
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein

Fred,
Could you elaborate on this please. How will it work in the final release?
Could you elaborate on this please. How will it work in the final release?
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein

That's easy to say but:
- My IDE gets written to in codepage and not UTF8 (even though it's set to UTF 8 ) so I can't manually put anything in in that format unless I convert from cp932 to utf16 (and then back to utf8?)
- If I do insert from utf8 files I have to convert everything on the fly between utf8 and utf16 in order to use string functions and display
- I'm not aware of a win32api utf8 version. :roll:
The easiest way to go is use the same thing throughout, CP or UTF16. UTF8 is probably the most work, converting and inconvenience. Since the IDE doesn't support UTF16 this makes the decision even easier....
Avoid unicode like the plague unless it's absolutely necessary and no workarounds are available (and then go UTF16).
- My IDE gets written to in codepage and not UTF8 (even though it's set to UTF 8 ) so I can't manually put anything in in that format unless I convert from cp932 to utf16 (and then back to utf8?)
- If I do insert from utf8 files I have to convert everything on the fly between utf8 and utf16 in order to use string functions and display
- I'm not aware of a win32api utf8 version. :roll:
The easiest way to go is use the same thing throughout, CP or UTF16. UTF8 is probably the most work, converting and inconvenience. Since the IDE doesn't support UTF16 this makes the decision even easier....
Avoid unicode like the plague unless it's absolutely necessary and no workarounds are available (and then go UTF16).
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
I must be missing something or this whole thing is a non-issue. I develop for Japanese daily using PB in the same environment as you I think, and never encounter any issues.. are you talking about the PB IDE? Set it to UTF-8 & compile for unicode and forget.. Japanese chars can be typed in directly in the IDE & assigned to strings (compile for unicode of course). It just works.. no conversion issues (particularly when you are creating/dealing with characters yourself). There is absolutely no reason to avoid unicode like the plague.. unicode plus PB's implementation is very friendly for any non-English programming, and is one of the prime reasons why I personally use PB regularly.pdwyer wrote:My IDE gets written to in codepage and not UTF8
Last edited by mskuma on Mon Oct 22, 2007 2:14 pm, edited 1 time in total.
and not use the PB one you mean?
I like the built in IDE !! (something I never said about powerbasic, I always went 3rd party with them)
Actually, I'm happy using code pages till you guys recompile the IDE in unicode mode
I think it adds extra complexity building unicode apps in a non unicode IDE, I can't type japanese straight in.
As is, I can put a japanese interface app together as easy as an english one so I'm not really annoyed. I just thought Unicode might be easier (since mskuma is a diehard unicode apologist! he talked fast to me and I lost my way )
)
I like the built in IDE !! (something I never said about powerbasic, I always went 3rd party with them)
Actually, I'm happy using code pages till you guys recompile the IDE in unicode mode
I think it adds extra complexity building unicode apps in a non unicode IDE, I can't type japanese straight in.
As is, I can put a japanese interface app together as easy as an english one so I'm not really annoyed. I just thought Unicode might be easier (since mskuma is a diehard unicode apologist! he talked fast to me and I lost my way
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
-
LuCiFeR[SD]
- 666

- Posts: 1033
- Joined: Mon Sep 01, 2003 2:33 pm
If you set the Sourcefile Text Encoding to UTF8 as Fred and LuCiFeR[SD] say, you can type Japanese (or any other non-English) language directly into the editor. It may be easiest to set this via 'Compiler Options' button [next to the compile/run button], see 2nd last option on this options form.pdwyer wrote:I can't type japanese straight in.
Generally if you compile as unicode, you'll see these chars appear in the application.
I have set it on the compiler options button already, I think it's set by default. (or atleast I don't remember making that change).
I'll try the "Preferences/Editor/Defaults" location too as I didn't change that one, not sure if there's a difference.
I'll double check when I get home but I'm fairly sure if not using UTF8.
If in ascii mode compile I can type cp932 into the IDE and it displays fine, debugs fine and GUI code works (menu's, gadgets etc) so no problem in that sense.
In unicode mode, I can type cp932 into the IDE and it looks fine but it won't display compiled anywhere, messagerequester() gadgets etc all show garbage, conversion works poorly if cp92 is compiled straight in to unicode app.
I'll try the "Preferences/Editor/Defaults" location too as I didn't change that one, not sure if there's a difference.
I'll double check when I get home but I'm fairly sure if not using UTF8.
If in ascii mode compile I can type cp932 into the IDE and it displays fine, debugs fine and GUI code works (menu's, gadgets etc) so no problem in that sense.
In unicode mode, I can type cp932 into the IDE and it looks fine but it won't display compiled anywhere, messagerequester() gadgets etc all show garbage, conversion works poorly if cp92 is compiled straight in to unicode app.
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
OK, That's pretty special! 
I'm not sure if it's a bug in the IDE or if it's two different settings.
The compile options was always set to UTF8 but the preferences was set to plain text. When I changed the preferences to UTF8 then unicode works for Japanese which is great.
Also, the internal debugger works for japanese in unicode now which is great but Mistrel and Freak said it wasn't supposed to!
Now I'll have to try a whole lot of things all over again, I thought the compiler options is what people were talking about, wonder what that is then...
I'm not sure if it's a bug in the IDE or if it's two different settings.
The compile options was always set to UTF8 but the preferences was set to plain text. When I changed the preferences to UTF8 then unicode works for Japanese which is great.
Also, the internal debugger works for japanese in unicode now which is great but Mistrel and Freak said it wasn't supposed to!
Now I'll have to try a whole lot of things all over again, I thought the compiler options is what people were talking about, wonder what that is then...
Paul Dwyer
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
“In nature, it’s not the strongest nor the most intelligent who survives. It’s the most adaptable to change” - Charles Darwin
“If you can't explain it to a six-year old you really don't understand it yourself.” - Albert Einstein
I've read before that doesn't, however for the internal debugger window, the regional options setting 'display non-unicode characters as ..' (Japanese) is what's responsible for making it display properly there.pdwyer wrote:Also, the internal debugger works for japanese in unicode now which is great but Mistrel and Freak said it wasn't supposed to!
I guess it's simply reporting a 2-byte length for a unicode char?wonder what that is then...