Page 1 of 1
URLEn/Decoder with ASCII and UTF8 flag
Posted: Sun Dec 21, 2008 10:47 pm
by mback2k
Hello everyone,
I would really like to see the URLDecoder function support different character sets, because of the following problem:
Source code:
Code: Select all
Procedure.s UTF8ToString(UTF8$)
Protected String$ = Space(StringByteLength(UTF8$, #PB_Ascii)+1)
PokeS(@String$, UTF8$, -1, #PB_Ascii)
ProcedureReturn PeekS(@String$, -1, #PB_UTF8)
EndProcedure
Test$ = "H:/Musik/Die%20%C3%84rzte/13/15%20Nie%20gesagt.mp3"
Debug Test$
Debug URLDecoder(Test$)
Debug UTF8ToString(URLDecoder(Test$))
Code: Select all
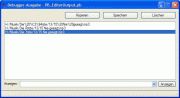
H:/Musik/Die%20%C3%84rzte/13/15%20Nie%20gesagt.mp3
[removed this line - please look at the image]
H:/Musik/Die Ärzte/13/15 Nie gesagt.mp3
Code: Select all
H:/Musik/Die%20%C3%84rzte/13/15%20Nie%20gesagt.mp3
[removed this line - please look at the image]
H:/Musik/Die ?rzte/13/15 Nie gesagt.mp3
The difference is in the last line, in Unicode mode the "Ä" is replaced with a "?". I tried various PeekS/PokeS combinations, but I cannot get it to work, because the string returned by URLDecoder (2nd line) is already invalid.
Thanks in advance!
Posted: Mon Dec 22, 2008 11:24 am
by mback2k
Appendix to my first post:
Basically the URLEncoder and URLDecoder functions need to be able to encode and decode to UTF8 %-encoded URLs.
ASCII: URLEncoder("Ä") = %C4
UTF8: URLEncoder("Ä") = %C3%84
ASCII: URLDecoder("%C4") = Ä
UTF8: URLDecoder("%C3%84") = Ä
The executables Unicode/Ascii switch should not have any effect on this.
Posted: Mon Dec 22, 2008 12:14 pm
by mback2k
Sorry for multiple postings, but I want to keep you guys up to date on the problem.
I managed to create working functions that always do the same in ASCII and Unicode mode:
Code: Select all
Procedure.s URLEncode(URL$)
Protected Result$, Char$, Char, Index, *Buffer
For Index = 1 To Len(URL$)
Char$ = Right(Left(URL$, Index), 1)
Char = Asc(Char$)
If Char < 128
If (Char > 32 And Char <> 37 And Char <> 34 And Char <> 60 And Char < 62) Or (Char > 62 And Char < 91) Or (Char > 94 And Char <> 96 And Char < 123) Or (Char = 126)
Result$ + Char$
Else
Result$ + "%" + RSet(Hex(Char), 2, "0")
EndIf
Else
*Buffer = AllocateMemory(4)
If *Buffer
PokeS(*Buffer, Char$, -1, #PB_UTF8)
Result$ + "%" + RSet(Hex(PeekB(*Buffer)&$FF), 2, "0") + "%" + RSet(Hex(PeekB(*Buffer+1)&$FF), 2, "0")
FreeMemory(*Buffer)
EndIf
EndIf
Next
ProcedureReturn Result$
EndProcedure
Procedure.s URLDecode(URL$)
Protected Result$, Char$, Char, Index, *Buffer
Result$ = URL$
Index = FindString(URL$, "%", 1)
If Index
Repeat
Char$ = Right(Left(Result$, Index+2), 2)
Char = Val("$"+Char$)
If Char < 128
Result$ = ReplaceString(Result$, "%"+Char$, Chr(Char))
ElseIf Right(Left(Result$, Index+3), 1) = "%"
*Buffer = AllocateMemory(4)
If *Buffer
PokeB(*Buffer, Char)
PokeB(*Buffer+1, Val("$"+Right(Left(Result$, Index+5), 2)))
Result$ = ReplaceString(Result$, Right(Left(Result$, Index+5), 6), PeekS(*Buffer, -1, #PB_UTF8))
FreeMemory(*Buffer)
EndIf
EndIf
Index = FindString(Result$, "%", Index+1)
Until Not Index
EndIf
ProcedureReturn Result$
EndProcedure
Procedure.s DummyString1()
Protected Result$, Char
For Char = 32 To 126
Result$ + Chr(Char)
Next
ProcedureReturn Result$
EndProcedure
Procedure.s DummyString2()
Protected Result$, Char
For Char = 128 To 255
Result$ + Chr(Char)
Next
ProcedureReturn Result$
EndProcedure
DummyString1$ = DummyString1()
DummyString2$ = DummyString2()
If URLEncoder(DummyString1$) = URLEncode(DummyString1$)
Debug "ASCII Test 1 passed!"
Else
Debug "ASCII Test 1 failed!"
EndIf
If URLDecode(URLEncode(DummyString1$)) = DummyString1$
Debug "ASCII Test 2 passed!"
Else
Debug "ASCII Test 2 failed!"
EndIf
If URLDecode(URLEncode(DummyString2$)) = DummyString2$
Debug "UTF8 Test passed!"
Else
Debug "UTF8 Test failed!"
EndIf
Fred, any chance to have PB's functions updated?
The only problem that still exists is that you can't use LCase or UCase with the returned string in Unicode mode

Posted: Mon Dec 22, 2008 7:06 pm
by Trond
1. You don't describe what output is the correct one, so we can't know what you want.
2. In the code from the first post you treat a PB string as an UTF-8 strings. That's not possible. PB strings are ascii in ascii mode and UCS2 in unicode mode, trying to treat them as something different will make things break in unexpected ways. If you need to store a string in a specific format, store it in a memory buffer. I can see from your code that it will defintely break in unicode mode, maybe it won't in ascii mode.
3. The internal debug output doesn't support unicode characters. No matter if your string was ever so correctly returned from your functions it would show up as ???? if it was made of unicode characters. Use the external debugger to see what you're doing.
4. I don't have the problem here. To my surprise the last line shows an Ä in both unicode and ascii mode. I have no good explanation for this, as in my theory, it should break!
5. If URLDecoder() doesn't support unicode in ascii mode, then that's your own problem and what we have unicode mode for.
6. If URLDecoder() doesn't support unicode in unicode mode, then it sounds like a bug and you should post a simple piece of code to show it in the bug report section. If it's following RFC 3986 then the current behaviour is buggy, but I don't know which RFC it's following.
Posted: Mon Dec 22, 2008 7:24 pm
by mback2k
1. I thought that is clear. The ASCII screen is correct.
2. But I don't want that. I want to decode the string as UTF8 and store it in ASCII or Unicode, depending on the compilation switch.
3. I am using the external debugger, because I am using jaPBe. At least it's running PBDebuggerUnicode.exe.
4. It does show an "?" in Unicode, and that is wrong.
5. I am not an idiot, thanks for treating me like one.
6. It's not following the RFCs, because %-encoded URLs can contain ASCII and UTF8 characters in %-form. If the first %xx is higher than 127 (out of ASCII range), it's a 2-byte UTF8 character that is represented by %xx%xx.
I provided 2 functions that do follow the RFCs and it works. The only thing that is still not working for me is the transfer from UTF8 encoding to Unicode.
I am trying to explain this as good as possible, but English is not my native language, so excuse any unwanted rudeness.
Re: URLEn/Decoder with ASCII and UTF8 flag
Posted: Fri Feb 12, 2010 2:14 pm
by dige
UTF-8 is recommended by RFC 3986.
http://tools.ietf.org/html/rfc3986
http://en.wikipedia.org/wiki/URL_Encoding
and should be also supported

+1 for URLEncoder (url.s, [flags])
flags: #PB_UTF-8 , #PB_ASCII
Re: URLEn/Decoder with ASCII and UTF8 flag
Posted: Thu Oct 09, 2014 9:52 am
by Little John
After several years, this is still a "hot topic".
+1 from me for this wish.
Until this feature will be built into PB, we can use two small procedures which I posted
here.
Re: URLEn/Decoder with ASCII and UTF8 flag
Posted: Thu Oct 09, 2014 2:19 pm
by davido
+1
Odd omission. I assumed PureBasic was moving into the future with the impending switch to Unicode.
Re: URLEn/Decoder with ASCII and UTF8 flag
Posted: Wed Dec 03, 2014 12:44 am
by eddy
+1
Re: URLEn/Decoder with ASCII and UTF8 flag
Posted: Fri Sep 04, 2015 8:37 pm
by Little John
Implemented in PB 5.40.