Page 1 of 2
Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 5:11 pm
by PrincieD
Hi guys!
Can anyone help me squeeze as much speed as possible out of the following
image FilterCallback? Maybe some Asm code? (has to run on both x86 x64):
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
r = Red(TargetColor)
g = Green(TargetColor)
b = Blue(TargetColor)
a = Alpha(TargetColor)
sa = Alpha(SourceColor)
a = (a/255.0)*(sa)
r = (r/255.0)*(sa)
g = (g/255.0)*(sa)
b = (b/255.0)*(sa)
ProcedureReturn RGBA(r, g, b, a)
EndProcedure
The callback takes the alpha channel of the target and combines it with the source (alpha mask) using an
image that already has pre-multiplied alpha.
Many thanks!
Chris.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 5:24 pm
by Thorium
Simple dont use a callback. Just access the image data directly. A callback means a call for every pixel, which is extremly slow.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 6:55 pm
by STARGÅTE
@Thorium:
With access you need all pixels too.
FilterCallback() is not slow!
@PrincieD:
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
Protected.i R, G, B, A
Protected S.f
R = TargetColor & $FF
G = TargetColor>>8 & $FF
B = TargetColor>>16 & $FF
A = TargetColor>>24 & $FF
S = Alpha(SourceColor)/255.0
R * S
G * S
B * S
A * S
ProcedureReturn R | G<<8 | B<<16 | A<<24
EndProcedure
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 7:06 pm
by PrincieD
Thanks very much STARGÅTE!

the speed has doubled now!
Would coding the same algorithm using asm make much of a difference?
Thanks!
Chris.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 7:14 pm
by STARGÅTE
PrincieD wrote:Would coding the same algorithm using asm make much of a difference?
Yes, because then you can work with the registers optimized!
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 7:50 pm
by PrincieD
STARGÅTE wrote:PrincieD wrote:Would coding the same algorithm using asm make much of a difference?
Yes, because then you can work with the registers optimized!
Cool cool

just wanted to confirm before spending lots of time coding in asm ugh lol
Thorium wrote:Simple dont use a callback. Just access the image data directly. A callback means a call for every pixel, which is extremly slow.
Thanks Thorium, I thought this would be the case too but I tried using GetDIBits/SetDIBits but was really slow compared to PB's filter callback method

Chris.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 8:24 pm
by wilbert
If you don't mind the result can be 1 off compared to the original function (like $62728292 instead of $63738393), you can try this
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
!pxor xmm0, xmm0
!movd xmm1, [p.v_TargetColor]
!punpcklbw xmm0, xmm1
!movd xmm1, [p.v_SourceColor]
!psrld xmm1, 24
!punpcklbw xmm1, xmm1
!pshuflw xmm1, xmm1, 0
!pmulhuw xmm0, xmm1
!psrlw xmm0, 8
!packuswb xmm0, xmm0
!movd eax, xmm0
ProcedureReturn
EndProcedure
if you want the same result, you can try this but it's a little bit slower compared to the procedure above but still faster compared to the non asm code
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
!movd xmm0, [p.v_TargetColor]
!pxor xmm1, xmm1
!punpcklbw xmm0, xmm1
!punpcklwd xmm0, xmm1
!cvtdq2ps xmm0, xmm0
!mov eax, dword [p.v_SourceColor]
!shr eax, 24
!cvtsi2ss xmm1, eax
!mov eax, 255
!cvtsi2ss xmm2, eax
!divss xmm1, xmm2
!pshufd xmm1, xmm1, 0
!mulps xmm0, xmm1
!cvtps2dq xmm0, xmm0
!packssdw xmm0, xmm0
!packuswb xmm0, xmm0
!movd eax, xmm0
ProcedureReturn
EndProcedure
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 9:06 pm
by PrincieD
wilbert wrote:If you don't mind the result can be 1 off compared to the original function (like $62728292 instead of $63738393), you can try this to see if it is faster
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
!pxor xmm0, xmm0
!movd xmm1, [p.v_TargetColor]
!punpcklbw xmm0, xmm1
!movd xmm1, [p.v_SourceColor]
!psrld xmm1, 24
!punpcklbw xmm1, xmm1
!pshuflw xmm1, xmm1, 0
!pmulhuw xmm0, xmm1
!psrlw xmm0, 8
!packuswb xmm0, xmm0
!movd eax, xmm0
ProcedureReturn
EndProcedure
That's awesome wilbert!! really fast now

thanks!
I might try the GetDIBits/SetDIBits method again though (to avoid the JMP/RET every pixel, is that what PB is doing with the filtercallback?), I think I might have been doing something wrong.
My "rough n' ready" AlphaMaskBlit code (from the new ProGUI GDI drivers) currently looks like this anyway:
Code: Select all
If timage = #Null
timage = CreateImage(#PB_Any, w, h, 32)
EndIf
hdc = StartDrawing(ImageOutput(timage))
BitBlt_(hdc, 0, 0, w, h, *src\sBuf\hdc, src\left, src\top, #SRCCOPY)
DrawingMode(#PB_2DDrawing_CustomFilter)
CustomFilterCallback(@FilterCallback())
*dstmask.masks = *dstImg\mask
test = GrabImage(*dstmask\handle, #PB_Any, dst\left-*dst\rc\left, dst\top-*dst\rc\top, w, h)
DrawImage(ImageID(test), 0, 0)
FreeImage(test)
GdiAlphaBlend_(*dst\sBuf\hdc, dst\left, dst\top, dw, dh, hdc, 0, 0, w, h, $1000000 | alpha<<16)
StopDrawing()
It copies the source
image (with alpha already
premultiplied) from a section of the source superbuffer
image into a temporary
image (timage) using BitBlt.
Then grabs the corresponding section of the alphamask and draws it into the temporary
image using the filtercallback to combine the alphas.
Finally the temporary
image is then alpha blended onto a section of the destination superbuffer using hardware accelerated GdiAlphaBlend.
I'm just wondering if there's a better way to do it, if I could get rid of any unnecessary blit operations then the speed would be doubled again hmm
Thanks anyway guys, I really appreciate the help!
Chris.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 9:50 pm
by Thorium
PrincieD wrote:
Thorium wrote:Simple dont use a callback. Just access the image data directly. A callback means a call for every pixel, which is extremly slow.
Thanks Thorium, I thought this would be the case too but I tried using GetDIBits/SetDIBits but was really slow compared to PB's filter callback method
Chris.
Why use GetDIBits/SetDIBits? PB offers direct buffer access with: DrawingBuffer()
And callbacks are very slow, you have many unnecessary operations per pixel including a call, which is allways slow. The good thing about the filter callbacks is that they are easy to use, not that they are fast.
Without ASM the loop would look like that: (untested)
Code: Select all
Structure Pixel_BGRA
Blue.a
Green.a
Red.a
Alpha.a
EndStructure
Procedure DoStuff(*SrcBuffer, *DstBuffer, Height.i, Width.i, SrcPitch.i, DstPitch.i)
Protected *SrcPixel.Pixel_BGRA
Protected *DstPixel.Pixel_BGRA
Protected X.i
Protected Y.i
Protected S.f
Height - 1
For Y = 0 To Height
*SrcPixel = *SrcBuffer + (SrcPitch * Y)
*DstPixel = *DstBuffer + (DstPitch * Y)
For X = 1 To Width
S = *SrcPixel\Alpha / 255.0
*DstPixel\Blue = *DstPixel\Blue * S
*DstPixel\Green = *DstPixel\Green * S
*DstPixel\Red = *DstPixel\Red * S
*DstPixel\Alpha = *DstPixel\Alpha * S
*SrcPixel + 4
*DstPixel + 4
Next
Next
EndProcedure
Now you can speed this up by at least 5 times with ASM.
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 10:50 pm
by STARGÅTE
@Thorium:
The function DoStuff(...) is good, if you want apply it on a rectangle.
With a FilterCallback
all drawing functions will be work with this callback.
So if my mask is a circle FilterCallback() works too:
Code: Select all
Enumeration
#Window
#Gadget
EndEnumeration
OpenWindow(#Window, 0, 0, 800, 600, "WindowTitle", #PB_Window_MinimizeGadget|#PB_Window_ScreenCentered)
CanvasGadget(#Gadget, 0, 0, WindowWidth(#Window), WindowHeight(#Window))
Procedure Invert(X, Y, SourceColor, TargetColor)
ProcedureReturn ~TargetColor
EndProcedure
If StartDrawing(CanvasOutput(#Gadget))
DrawingMode(#PB_2DDrawing_Gradient)
LinearGradient(0,0,800,0) : GradientColor(0.0, $FF0000) : GradientColor(1.0, $0000FF)
Box(0,0,800,600)
DrawingMode(#PB_2DDrawing_CustomFilter)
CustomFilterCallback(@Invert())
Ellipse(300, 300, 250, 100)
Ellipse(500, 300, 200, 250)
StopDrawing()
EndIf
Repeat
Until WaitWindowEvent() = #PB_Event_CloseWindow
an other example with text:
Code: Select all
Enumeration
#Window
#Gadget
#Font
EndEnumeration
OpenWindow(#Window, 0, 0, 768, 256, "WindowTitle", #PB_Window_MinimizeGadget|#PB_Window_ScreenCentered)
CanvasGadget(#Gadget, 0, 0, WindowWidth(#Window), WindowHeight(#Window))
LoadFont(#Font, "Arial", 62)
Procedure Rotate(X, Y, SourceColor, TargetColor)
If SourceColor & $FF000000 And Random(1)
ProcedureReturn RGB(Green(TargetColor),Blue(TargetColor),Red(TargetColor))
Else
ProcedureReturn TargetColor
EndIf
EndProcedure
If StartDrawing(CanvasOutput(#Gadget))
DrawingMode(#PB_2DDrawing_Gradient)
LinearGradient(0,0,768,0) : GradientColor(0.0, $FF0000) : GradientColor(1.0, $0000FF)
Box(0,0,768,256)
DrawingFont(FontID(#Font))
DrawingMode(#PB_2DDrawing_CustomFilter|#PB_2DDrawing_Transparent)
CustomFilterCallback(@Rotate())
DrawText(32, 64, "Some drawed text!")
StopDrawing()
EndIf
Repeat
Until WaitWindowEvent() = #PB_Event_CloseWindow
Re: Help optimising small FilterCallback
Posted: Wed Sep 12, 2012 11:08 pm
by PrincieD
@Thorium: Good code man works well at the same speed as STARGÅTE's, I might be able to get rid of one of the blit steps using this method and combined with wilbert's kick ass ASM should be plenty fast
@STARGÅTE: good point!
I'll experiment further with the different methods, at least all are faster than my original code anyway

This is how it looks running on the Direct2D drivers with a 1000 balls at 60fps no performance hit (0% CPU usage) as Direct2D supports alpha masks on the GPU:
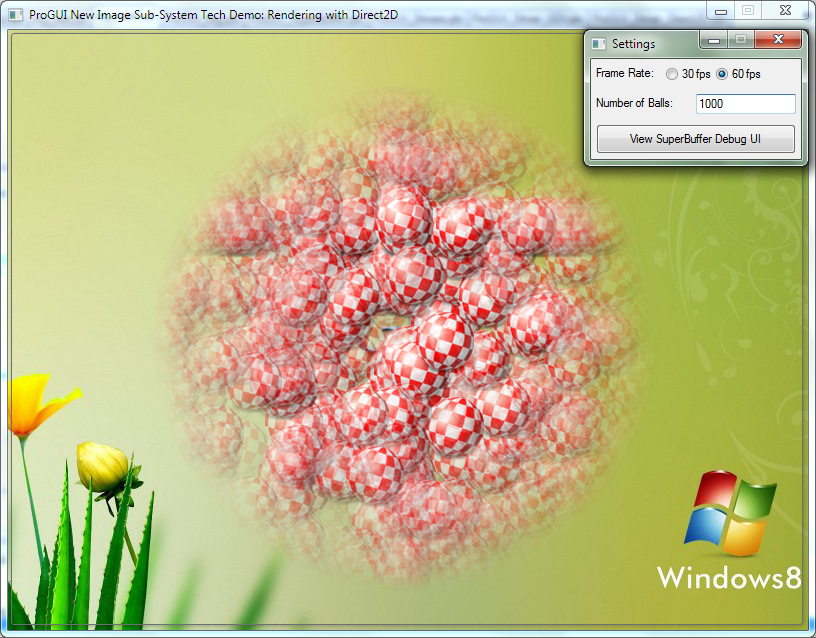
So far wilbert's asm can handle 100 balls at 60fps (24% CPU usage) using the GDI drivers, not too bad - hopefully we can squeeze a bit more speed out of it!

Chris.
Re: Help optimising small FilterCallback
Posted: Thu Sep 13, 2012 7:03 am
by wilbert
Compared to my previous procedure, this is a little bit faster and shorter but you will never get gpu speeds.
This code is the same for x86 and x64.
Code: Select all
Procedure FilterCallback(x, y, SourceColor, TargetColor)
!movd xmm1, [p.v_SourceColor]
!movd xmm0, [p.v_TargetColor]
!punpcklbw xmm1, xmm1
!punpcklbw xmm0, xmm0
!pshuflw xmm1, xmm1, 0xff
!pmulhuw xmm0, xmm1
!psrlw xmm0, 8
!packuswb xmm0, xmm0
!movd eax, xmm0
ProcedureReturn
EndProcedure
Combined with the approach from Thorium it could be something like this for x64.
Code: Select all
Procedure AlphaMultiply(*SrcBuffer, *DstBuffer, Height.i, Width.i, SrcPitch.i, DstPitch.i)
!movq xmm2, [p.p_SrcBuffer]
!movq xmm3, [p.p_DstBuffer]
!movq xmm4, [p.v_SrcPitch]
!movq xmm5, [p.v_DstPitch]
!alpha_multiply_loop0:
!movq rax, xmm2
!movq rdx, xmm3
!mov rcx, qword [p.v_Width]
!alpha_multiply_loop1:
!movd xmm1, [rax]
!movd xmm0, [rdx]
!punpcklbw xmm1, xmm1
!punpcklbw xmm0, xmm0
!pshuflw xmm1, xmm1, 0xff
!pmulhuw xmm0, xmm1
!psrlw xmm0, 8
!packuswb xmm0, xmm0
!movd [rdx], xmm0
!add rax, 4
!add rdx, 4
!dec rcx
!jnz alpha_multiply_loop1
!paddq xmm2, xmm4
!paddq xmm3, xmm5
!dec qword [p.v_Height]
!jnz alpha_multiply_loop0
EndProcedure
For x86 with sse instead of sse2 so it also runs on older hardware.
Code: Select all
Procedure AlphaMultiply(*SrcBuffer, *DstBuffer, Height.i, Width.i, SrcPitch.i, DstPitch.i)
!movd mm2, [p.p_SrcBuffer]
!movd mm3, [p.p_DstBuffer]
!movd mm4, [p.v_SrcPitch]
!movd mm5, [p.v_DstPitch]
!alpha_multiply_loop0:
!movd eax, mm2
!movd edx, mm3
!mov ecx, dword [p.v_Width]
!alpha_multiply_loop1:
!movd mm1, [eax]
!movd mm0, [edx]
!punpcklbw mm1, mm1
!punpcklbw mm0, mm0
!pshufw mm1, mm1, 0xff
!pmulhuw mm0, mm1
!psrlw mm0, 8
!packuswb mm0, mm0
!movd [edx], mm0
!add eax, 4
!add edx, 4
!dec ecx
!jnz alpha_multiply_loop1
!paddd mm2, mm4
!paddd mm3, mm5
!dec dword [p.v_Height]
!jnz alpha_multiply_loop0
!emms
EndProcedure
Re: Help optimising small FilterCallback
Posted: Thu Sep 13, 2012 4:19 pm
by Thorium
Note: You can access a rectangle of destination and source
image without any performance hit by adjusting the values of *DstBuffer, *SrcBuffer (first pixels to be processed) and DstPitch, SrcPitch (length of a
image line in memory). Just make The buffer pointer point to the first pixel and calculate the pitch so that it will go to the pixel in same column in the next line.
STARGÅTE wrote:
So if my mask is a circle FilterCallback() works too:
Yes, with different shapes it becomes a little bit more complicated, but not to much.
The big plus of the code is that you can process multiple pixels at once with smart SIMD code. Even without you can unrole the loop and process multiple pixel per iteration to reduce loop overhead.
Re: Help optimising small FilterCallback
Posted: Fri Sep 14, 2012 5:07 am
by PrincieD
Thanks for the help guys! especially Wilbert for his excellent ASM (it would have taken me forever to attempt this and probably wouldn't be as fast!

). I think I'll go with the filtercallback method as this seems the most versatile and runs quickest with the new smaller ASM algorithm. Thorium, thanks for pointing me in the direction of SIMD too - this could potentially be even quicker but I think it may be a bit over my head lol (might try and experiment tomorrow, I'm pretty tired now heh).
Cheers!
Chris.
Re: Help optimising small FilterCallback
Posted: Fri Sep 14, 2012 7:11 am
by wilbert
Glad to help
And when it comes to SIMD, there are different ways you could approach the problem.
In a loop, you could process multiple pixels at once and that might be faster.
The callback as it as now however also uses SIMD instructions but in this case to handle the four color channels at once.