Das ist ein sehr komplexes Thema, was vermutlich nicht so einfach in ein paar Zeilen erklärt ist. Es wird sicherlich auch viele verschiedene Herangehensweisen geben, die alle ihre Vor- und Nachteile haben.
Wenn ich (übrigens ohne Grundlagenwissen zu diesem Thema) so etwas angehen müsste (freiwillig würde ich mir das nicht antun), dann gäbe es mehrere Bearbeitungsschritte, die das Bild mit dem Text durchlaufen müsste.
Zuerst sollte man dafür sorgen, dass sich der Text sehr gut vom eigentlichen Hintergrund abhebt. Also quasi als Grundvoraussetzung. Selbst heutige Hochleistungsalgorithmen zur Texterkennung werden jämmerlich versagen, wenn Text und Hintergrund irgend ein kontrastloses Gemansche darstellen.
So nicht:

Wenn man den Text dann durch Kontrast- oder Gammakorrektur oder anderweitige Maskierung dann mehr oder weniger sauber freigestellt hat, dann sollte man die Farbinformationen eliminieren und den Text als schwarz/weiß Grafik vorliegen haben.
Danach sollte man erkennen in welchem Bereich sich der Text befindet und, ob die Vorlage korrekt horizontal ausgerichtet ist. Falls nötig muss das gesamte Bild dann um den entsprechenden Betrag gedreht werden, damit die einzelnen Sätze des Textes exakt horizontal ausgerichtet sind, weil die nachfolgende Erkennung sonst nicht funktioniert.

Im nächsten Schritt würde ich versuchen den Raum zu erkennen, den die einzelnen Sätze einnehmen. Also so, dass man später mehrere rechteckige Bereiche untereinander definiert hat, von denen man weiß, dass sich darin jeweils genau ein Satz mit mehreren Wörtern befindet (siehe unten rot).
Der nächste Schritt müsste dann in jedem dieser Rechtecke (= Sätze) versuchen die einzelnen Wörter voneinander zu trennen, so dass das Programm genau weiß von welcher X1 Position bis zu welcher X2 Position innerhalb des Rechtecks sich ein Wort befindet (siehe unten blau). Die genauen Algorithmen hierfür kann ich nicht aus der Hand schütteln. Das ist wie gesagt sicherlich nicht ganz trivial. In dem Fall hier kann man versuchen die Lücken ohne Pixel zwischen den Worten zu erkennen und dann mit einer gewissen Toleranz festlegen was das Ende eines Wortes ist.
Danach geht man weiter ins Detail und isoliert auf die gleiche Weise die einzelnen Buchstaben voneinander, so dass das Programm weiß welchen Raum ein einzelner Buchstabe in einem Wort einnimmt (siehe unten grün).
Ungefähr so:

Jetzt weiß das Programm wo welcher Buchstabe liegt und welche Dimension dieser einnimmt.
Zur Erkennung eines Buchstabens brauchst Du dann ein System, das Muster unabhängig von der Größe der Buchstaben erkennen kann. Es nütz Dir ja nichts, wenn Du einfach nur ein festes Bitmuster erkennen kannst, bei dem jeder Buchstabe z.B. genau 20 x 40 Pixel groß sein muss.
Ohne es jemals versucht zu haben, würde ich es so angehen:
Das Rechteck eines Buchstaben würde ich z.B. in 25 Reihen und 25 Spalten einteilen
Hier mal angedeutet:
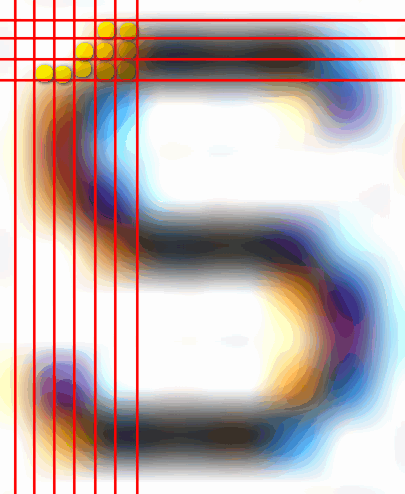
Dann geht man das Raster durch und "markiert" jedes Feld, das Teil des Buchstabens ist. Hier mit den Kreisen angedeutet. Dein Programm muss für jeden zu erkennenden Buchstaben eine Art "Vergleichstabelle" haben, die alle Felder enthält, die für den jeweiligen Buchstaben gesetzt sind (also Teil des Buchstabens sind).
Für jede Zeile muss man also anhand der markierten Felder vergleichen mit welchen Buchstaben aus der Vergleichstabelle diese Zeile am ehesten übereinstimmt. Die x besten Übereinstimmungen notiert man sich dann pro Zeile.
Mal ein vereinfachtes Beispiel für das "A":
Rechts neben den Zeilen stehen die Buchstaben, bei denen die Zeile ähnlich aussieht. Von links nach Rechts mit abnehmender Trefferquote.
Code: Alles auswählen
.###. A, T, C
#...# H, A, B
##### H, A, B, S
#...# H, A, B
#...# H, A, B
Dann geht man hin und ermittelt für jede Zeile die x besten Treffer und zieht daraus dann den Gewinner.
Wenn wir die 3 besten Treffer nehmen, dann haben wir hier also:
A = 5x (ist nämlich in jeder Zeile vorhanden)
H = 4x (ist in der ersten Zeile nicht vorhanden)
B = 4x (ist in der ersten Zeile nicht vorhanden)
Der Buchstabe mit der höchsten Trefferquote ist also das A.
Das ist natürlich alles nur sehr stark vereinfacht und das Prinzip, das ich hier beschrieben habe wird bei unterschiedlichen Ausführungen von gleichen Buchstaben jämmerlich versagen (Z.B. Serif und Sans Serif Schriften)...
...aber ich wollte es nur grob verdeutlichen, dass da ein bisschen mehr dran hängt, als man evtl. gedacht hat.
Man kann die Buchstaben sicherlich auch vertorisieren und dann die Ähnlichkeit der Vectorpfade vergleichen (Winkel, Steigungen, Längenverhältnisse etc.), aber das ist nichts worin ich mich auskenne.
Im nächsten Schritt, wenn dann also die Buchstaben und die Worte "erkannt" worden sind, kommen am besten noch Abgleiche mit einem Wörterbuch dran, um ein oder zwei falsch erkannte Buchstaben in einem Wort auf diese Weise korrigieren zu können.
Möglicherweise wurde durch ein paar unsaubere Pixel im Bild aus einem O ein Ö und es wurde "Sönne" statt "Sonne" erkannt. Das kann mit einem Wörterbuch und Ähnlichkeitsvergleich korrigiert werden.
Wer es drauf hat, kann dann noch eine Inhaltsprüfung programmieren, die erkennt, ob bestimmte Satzzusammenstellungen überhaupt gültig sind. Beispiel: "Des Ball springt". Alle Worte sind korrekt, aber der Satz ist falsch, weil statt des Wortes "Der" das Wort "Des" erkannt wurde.
Na ja, das nur mal als Gedankenanstoss von mir. Ich würde es nicht programmieren wollen.


